Cómo combatir ‘deepfakes’ y otros contenidos sintéticos (I): el Reglamento de IA y su Código de Buenas Prácticas apuestan por la transparencia
Cristina Mesa, socia de Propiedad Industrial e Intelectual en Garrigues.


Iniciamos una serie de cuatro entregas en las que analizaremos, desde distintos enfoques, los retos legales que plantean los deepfakes. El objetivo es ofrecer a los lectores las claves necesarias para comprender y abordar este fenómeno con rigor. En esta primera entrega nos centramos en el marco legal europeo y en cómo trata de identificar el origen de los contenidos generados o manipulados con inteligencia artificial. A continuación, abordaremos la respuesta desde los fundamentos del Derecho español frente a posibles estafas. Otro artículo analizará el papel y las obligaciones de las plataformas y, por último, cerraremos la serie con un juego para poner a prueba lo aprendido. (Lee aquí el segundo artículo de esta serie).
Deepfakes para estafas financieras, suplantación de identidad corporativa, desinformación política… La frontera entre lo real y lo sintético se ha evaporado, y el problema ya no es técnico ni futuro: es jurídico y presente. El artículo 50 del Reglamento europeo de Inteligencia Artificial (RIA) pretende luchar contra los usos ilícitos de la IA mediante obligaciones de transparencia que, si nada cambia, serán aplicables desde el 2 de agosto de 2026. Para ayudar con esta tarea, el pasado 30 de marzo se cerró el plazo de aportaciones del segundo Código de Buenas Prácticas sobre marcado y etiquetado de contenido generado con IA, que aborda como marcar, detectar y etiquetar el contenido sintético para que el usuario sepa cuándo está ante algo generado o manipulado por IA.
El problema
En noviembre de 2025, Berkshire Hathaway publicó un comunicado con un título elocuente: "It's Not Me". Videos generados con IA mostraban a Warren Buffett dando consejos de inversión que nunca dio, con una apariencia visual lo bastante convincente como para que el propio Buffett reconociera que podría haber caído en la trampa. En España, los fraudes del CEO mediante suplantación de voz con IA son ya un patrón recurrente que ha costado millones a empresas públicas y privadas.
El Parlamento Europeo advierte de la expansión de estafas basadas en clonación de voz y deepfakes, y señala que cerca del 50 % de las empresas analizadas ya han sufrido algún incidente de este tipo. Europol identifica el fraude habilitado por IA como una de las principales amenazas del crimen organizado en la Unión Europea, destacando su capacidad de automatización, escala y sofisticación. En España, aunque no existe todavía una estadística agregada anual, INCIBE y el CCN‑CERT han documentado múltiples casos reales de suplantación mediante clonación de voz, incluidos ataques dirigidos contra empresas a través de la suplantación de directivos para autorizar transferencias o desviar pagos, lo que confirma la materialidad del riesgo también a nivel nacional.
El segundo borrador: más flexible, igual de exigente
Respecto al primer borrador de diciembre de 2025, sobre el que ya escribimos aquí, el segundo Código de Buenas Prácticas es más flexible, más simplificado y técnicamente más realista. Se construye sobre obligaciones redundantes porque reconoce que no existe ninguna tecnología que, por sí sola, sea suficiente para combatir los deepfakes y la desinformación. Es un claro ejercicio de realismo que obliga a reconocer la enorme dificultad que entraña la lucha contra los malos usos de la inteligencia artificial.
Con el mismo objetivo de obtener apoyo de todos los agentes involucrados, el RIA impone obligaciones a lo largo de la cadena de valor entre dos grandes bloques: los proveedores, que deben incorporar el marcado técnico (las capas invisibles), y los responsables del despliegue, que asumen la transparencia visible ante el usuario final. El código responde a este diseño múltiple y se divide también en dos bloques, uno destinado a facilitar el marcado en origen y el otro a facilitar formas de etiquetado que ayuden a los usuarios finales a detectar los contenidos generados o manipulados con IA.
Proveedores: el enfoque multicapa
En relación con los proveedores, es decir, los fabricantes de los sistemas de IA, el código propone un sistema de marcado por capas que debe incluir, al menos, una capa de metadatos y una marca de agua, siendo opcional la adopción de técnicas adicionales como el finger printing o el uso de logs. Para los que no están familiarizados con estos términos, podemos explicarlos como sigue, junto con sus puntos fuertes y débiles:
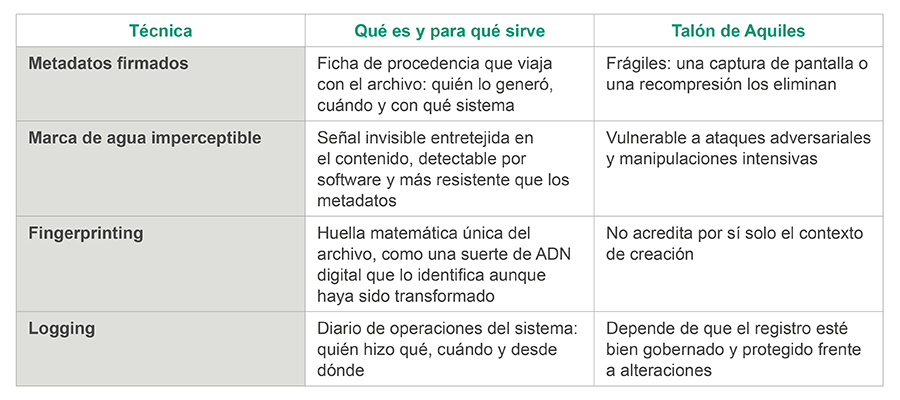
El artículo 50.2 exige además que estas soluciones cumplan cuatro criterios.
- Eficacia: que sirvan realmente para distinguir contenido humano de artificial.
- Interoperabilidad: que funcionen entre plataformas y formatos, sin ecosistemas cerrados.
- Robustez: que resistan tanto las transformaciones habituales como los ataques deliberados.
- Fiabilidad: que el sistema de detección no dispare falsos positivos ni negativos sin control.
No son adjetivos decorativos, sino los requisitos contra los que se medirá el cumplimiento.
Por otro lado, tenemos el problema de la “invisibilidad” de estas marcas para el común de los mortales. Para paliarlo, el código exige a los proveedores que habiliten vías de detección accesibles y gratuitas (p.ej., interfaz pública, API o herramienta equivalente) de forma que periodistas, investigadores y usuarios puedan verificar si un contenido presenta señales de origen artificial. No basta con que la marca exista, sino que tiene que poder ser consultada de forma razonablemente sencilla.
Un instrumento adicional con valor probatorio: el sello de tiempo cualificado
El marcado técnico documenta el origen, pero no certifica la integridad en el tiempo. Es decir, una marca de agua prueba que el contenido fue generado con IA, pero no que esa marca no fue añadida –o eliminada– después. Para cerrar esa brecha, existe un instrumento que el código no impone pero que encaja perfectamente con su lógica: los sellos de tiempo cualificados (QTS) bajo el Reglamento eIDAS. Ya hablamos de su utilidad en el contexto del software y los datos de entrenamiento, y lo que decíamos allí se traslada directamente a este escenario. ¿Por qué? Porque un QTS vincula criptográficamente el contenido con un momento exacto, dejando constancia de que ese archivo existía en ese estado preciso en esa fecha. El Derecho europeo le atribuye presunción de exactitud sobre la fecha y la integridad de los datos sellados, lo que en un litigio o en una auditoría regulatoria, puede ser la diferencia entre probar el cumplimiento y no poder hacerlo.
Responsables del despliegue: la transparencia visible
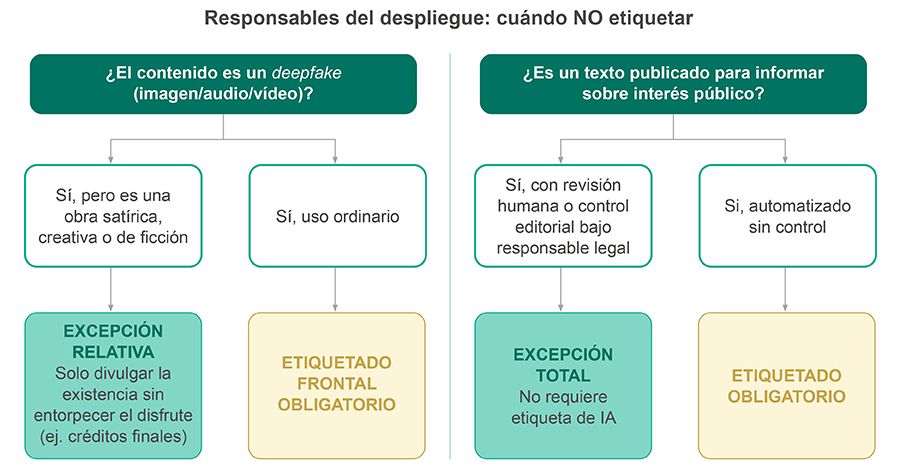
El segundo bloque del sistema se dirige a quienes publican o difunden contenido generado con IA. Para deepfakes de imagen, audio o vídeo, la obligación de divulgación es directa: informar de forma clara y distinguible que el contenido es sintético. Para textos sobre asuntos de interés público, también existe deber de divulgación, salvo que haya existido revisión humana o control editorial y alguien asuma la responsabilidad de la publicación.
El segundo borrador avanza en el diseño del etiquetado visible: requisitos de ubicación, uniformidad mínima, accesibilidad, y la posibilidad de un icono europeo común. La transparencia visible es una cuestión de interfaz y legibilidad, no solo de cumplimiento formal. El código intenta además evitar patrones oscuros, por lo que no basta con "poner algo" que diga IA, existen normas específicas de diseño, contraste y también modalidades de identificación dependiendo de la tipología de contenido (audiovisual, texto, etc.).
Por último, no debemos olvidarnos de las excepciones aplicables cuando el contenido forma parte de una obra evidentemente artística, creativa, satírica o ficticia, la obligación de transparencia no desaparece… pero se modula. En estos casos basta con revelar el uso de IA de una manera que no arruine la experiencia de la obra (p.ej., en los créditos finales). Es el punto donde el sistema reconoce que transparencia y libertad de creación deben convivir.
La paradoja que queda en el horizonte
Una cuestión incómoda que el código no resuelve, ni puede resolver solo, el llamado “dividendo del mentiroso”. Así, cuanto más acostumbramos a la sociedad a buscar etiquetas de IA, más fácil puede ser para un actor malicioso negar la autenticidad de algo verdadero explotando la ausencia de etiqueta. Esto nos lleva a tener en cuenta que la transparencia es necesaria, pero también puede convertirse en el telón de fondo para nuevas formas de negación.
Este problema no invalida el régimen establecido por el RIA y desarrollado por el código, pero nos recuerda que estamos construyendo una cadena de suministro digital de confianza en un entorno que seguirá siendo conflictivo por definición.
Calendario y próximos pasos
El código final se espera para principios de junio de 2026. Las obligaciones del artículo 50 serán exigibles desde el 2 de agosto de 2026, con una excepción: la obligación de marcado técnico legible por máquina del artículo 50.2 está sobre la mesa del trílogo con fechas distintas (febrero de 2027, según la Comisión; noviembre de 2026, según el Parlamento) sin que a día de hoy exista texto definitivo. En todo caso, la recomendación no cambia: hay que prepararse como si agosto fuera la fecha límite porque para la gran mayoría de las obligaciones de transparencia del artículo 50 lo es.