How to combat deepfakes and other synthetic content (I): the AI Act and its Code of Practice place transparency at the heart of the response
Cristina Mesa, partner in Garrigues' Intellectual Property Department and specializes in digital law


We are launching a series of four articles in which we will analyse, from different perspectives, the legal challenges posed by deepfakes. The aim is to provide readers with the key elements needed to understand and address this phenomenon with rigour. In this first article, we focus on the European legal framework and how it seeks to identify the origin of content generated or manipulated using artificial intelligence. We will then examine the response offered by the traditional foundations of Spanish law to potential fraud. Another article will analyse the role and obligations of platforms and, finally, we will close the series with a game designed to put what has been learned to the test.
Deepfakes that are used for financial scams, corporate impersonation, political disinformation, etc. The boundary between what is real and what is synthetic has disappeared, and the problem is no longer technical or confined to the future: it is legal and already here. Article 50 of the EU AI Act (AI Act) seeks to combat the unlawful use of AI through transparency obligations which, if everything goes to plan, will be applicable from August 2, 2026. To help with this task, the deadline for submissions to the second Code of Practice on Marking and Labeling of AI-generated content closed last March 30. The Code addresses how to mark, detect and label synthetic content so that users can detect when content has been generated or manipulated using AI.
The problem
In November 2025, Berkshire Hathaway issued a statement with an eloquent title: “It's Not Me”. AI-generated videos showed Warren Buffett giving investment advice that he had never actually given, with a visual appearance convincing enough for Buffett himself to admit that he might have been fooled. CEO fraud in Spain by AI-generated voice cloning have become a recurring pattern that is costing millions to both public and private businesses.
The European Parliament has warned about voice cloning scams and deepfakes and has indicated that close to 50% of the businesses analyzed have already suffered some such similar incident. Europol identifies AI‑enabled fraud as one of the main threats posed by organized crime in the EU, underscoring its capacity for automation, scale, and sophistication. In Spain, although no aggregated annual statistics are available yet, the Spanish National Cybersecurity Institute (INCIBE) and Spain’s National Cybersecurity Incident Response Team (CCN‑CERT) have documented numerous real‑world cases of impersonation through voice cloning, including targeted attacks against companies involving the impersonation of senior executives to authorize transfers or divert payments, confirming that the risk is also tangible at a national level as well.
The second draft: more flexible, equally demanding
With respect to the first draft from December 2025, which we wrote about here, the second Code of Practice is more flexible, more streamlined and technically more realistic. It is built on overlapping obligations, reflecting the recognition that no single technology alone, is sufficient to address deepfakes and disinformation. It is a clear exercise in realism, one that forces recognition of the enormous difficulty involved in tackling the misuse of AI.
With the same aim of obtaining support from all stakeholders, the AI Act imposes obligations throughout the value chain dividing them into two broad categories: providers, who must implement technical marking measures (the invisible layers), and deployers, who are responsible for ensuring visible transparency for end users. The Code reflects this multi‑layered approach, and it too is divided into two sections: one aimed at facilitating marking at origin, and the other at facilitating labeling mechanisms that help end users detect AI generated or manipulated content.
Providers: the multilayer approach
In relation to providers, that is, manufacturers of AI systems, the code proposes a layered marking system that must include, at least, a metadata layer and watermarking with optional fingerprinting and logging. For those who are not familiar with these terms, we explain them below, highlighting their strong and weak points:

Under article 50.2, these solutions must also fulfill four criteria:
- Effectiveness: they must be able to reliably distinguish human‑created content from artificially generated content.
- Interoperability: they must work across platforms and formats, without closed ecosystems.
- Robustness: they must be able to resist standard transformations and also deliberate attacks.
- Reliability: the detection system must not generate false positives or false negatives in an uncontrolled manner.
These are not merely descriptive labels, but rather the standards against which compliance will be measured.
We also have the problem of the “invisibility” of these markings for the average user. To mitigate this issue, the Code requires providers to make detection mechanisms available free of charge (i.e., public interface, an API, or an equivalent tool) so that journalists, researchers, and users can verify whether certain content shows signs of having been artificially generated. It is not enough for the markings to exist, they must be relatively easy for users to check.
An additional tool with evidentiary value: the qualified time stamp
Technical marking records the origin, but it does not certify integrity over time. That is, a watermark proves that the content was generated using AI, but not that this mark was not added, or eliminated, later. To address that shortcoming, there is a tool that the Code does not impose but which fits perfectly with its underlying logic: qualified time stamps (QTS) under the eIDAS Regulation. We had already examined its usefulness in the context of software and training data and what we said in that case applies equally here. Why? Because a QTS cryptographically links the content to a precise point in time, providing evidence that the file existed in that exact form on that specific date. European law confers a presumption of accuracy as to both the date and the integrity of the time‑stamped data, which, in a lawsuit or regulatory audit, can make the difference between being able to demonstrate compliance and being unable to do so.
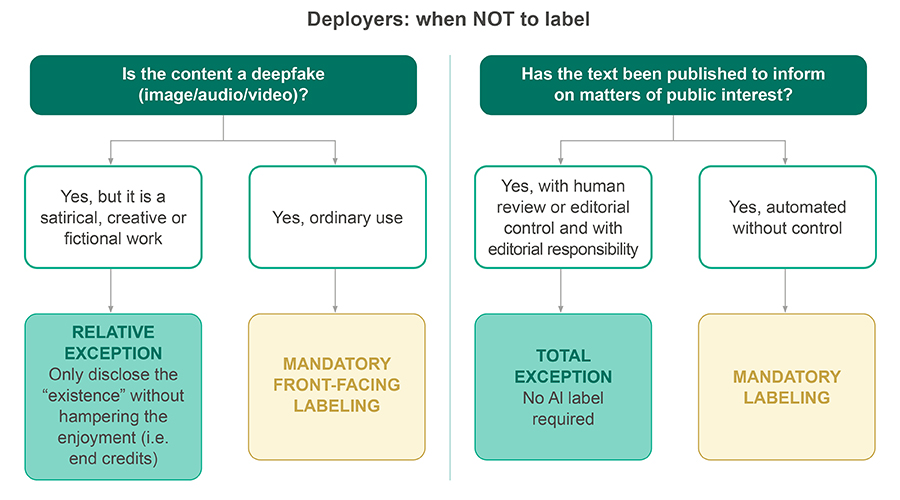
Deployers: visible transparency
Section two is directed at those who publish or disseminate AI-generated content. For image, audio, or video deepfakes, the disclosure obligation is straightforward: the content must be clearly and distinguishably identified as synthetic. For text relating to matters of public interest, a disclosure obligation is also applicable, unless the content has been subject to human review or editorial control and someone assumes responsibility for its publication.
The second draft further develops the design of visible labeling: placement, minimum uniformity and accessibility requirements as well as the possibility of a common European icon. Visible transparency is a matter of interface design and readability, not simply of formal compliance. The Code also seeks to avoid dark patterns: it is not sufficient to simply “add something” that says AI‑generated. Instead, it lays down specific rules on design and contrast, as well as different means of identification depending on the type of content involved (audiovisual, text, etc.).
Finally, we must not forget the applicable exceptions when the content forms part of an evidently artistic, creative, satirical or fictional work: the transparency obligation does not disappear, it is applicable proportionately. In those cases it is sufficient to disclose the use of AI in a way that does not ruin the experience of the work (i.e. in the end credits). This is the point at which the system recognizes that transparency and freedom of creation must coexist.
The paradox on the horizon
An uncomfortable aspect is that the code does not address and cannot address on its own, the so-called “liar’s dividend”. That is, the more we accustom society to look for AI labels, the easier it appears to be for a malicious actor to deny the authenticity of something that is genuine by exploiting the absence of such a label. This leads us to recognize that transparency is necessary, but that it can also become the backdrop for new forms of denial.
This problem does not undermine the regime established by the AI Act, which is developed by the Code, but it does remind us that we are building a digital supply chain of trust in an environment that will, by its very nature, remain contentious.
Timeline and next steps
The final version of the code is expected in early June 2026. The obligations set out in Article 50 will become enforceable as from August 2, 2026, with one exception: the obligation under Article 50.2 to implement machine‑readable technical marking is still under discussion in the trilogue, with different dates (February 2027 according to the Commission; November 2026 according to the Parliament), and no final text has yet been agreed. However, the recommendation remains the same: organizations should prepare on the basis that August is the deadline, since this is the case for the vast majority of the transparency obligations under Article 50.